

oh god, it's me
Welcome to Programmer Humor!
This is a place where you can post jokes, memes, humor, etc. related to programming!
For sharing awful code theres also Programming Horror.
oh god, it's me
Senior developer tip: squash the evidence.
Principle developer tip: rewrite history to make yourself seem smarter.
Soft reset the whole branch and commit a series of atomic and semantic patches (eg separating code, test, and refactor changes) that tell a clean narrative of the changeset to reviewers, future blamers.
And then my team squashes those commits 😩
Yeah it sucks. If the commits are really helpful, you can just paste the git log into the PR/MR/CR body after it's been merged
Do you put effort into your commit messages before the rewrite, or just write something quick for yourself and then put in the effort later?
Depends, but usually I will put in the effort up front and maybe tweak them in an in[eractive rebase, or just manually copy+paste.
If they're worth saving. Sometimes you have to kill your darlings though
git commit --amend --no-edit
This helped me countless times...
Senior developer tip: Squash ~~the evidence~~ management
F
git reset head~9
git add -A
git commit -am 'Rebased lol'
git push -f
F
🫂
It's a picture of the people who submit zero value comment spelling fixes to the Linux kernel so they can claim "I've submitted X patches to the Linux kernel" for KPIs or resume building
"Hey Bob, you've worked on the Linux kernel before, can you handle this CPU scheduler problem we're having? Shouldn't take you too long. We need it done before lunch"
"Nah I was in the network driver section"
"oh nice we're also having issues with random packets being dropped, can you look into that? It's business critical"
Listen bub, I don't have time for this Mickey mouse bullshit!
Hey man, I once had an engineering exec (who didn’t last very long) who decided engineers would be stack ranked by SLOC. You can imagine how easy that metric was to cheese, and you can also imagine exactly how that policy turned out.
Give an engineer a stupid metric to meet, and they’ll find a stupid way to meet it for you, if only out of malicious compliance.
I'd have a field day with that. Max line length 70 or 75, excessively verbose function and variable names, triple the normal amount of comments, extra whitespace wherever possible, tab width 8, etc. The possibilities are endless for that metric.
Dude... Just write a python script that makes small changes to white space every few seconds and commits them.
When metrics become targets they fail to be metrics any more
Campbell's law goes brrrrr.
Oh, you contributed to the kernel? Name every commit SHA.
Please use Conventional Commits. Simple and easy to use. Plus it is very easy so combine with Versioning techniques like Semantic Versioning.
Honestly, I've worked with a few teams that use conventional commits, some even enforcing it through CI, and I don't think I've ever thought "damn, I'm glad we're doing this". Granted, all the teams I've been on were working on user facing products with rolling release where main always = prod, and there was zero need for auto-generating changelogs, or analyzing the git history in any way. In my experience, trying to roughly follow 1 feature / change per PR and then just squash-merging PRs to main is really just ... totally fine, if that's what you're doing.
I guess what I'm trying to say is that while conv commits are neat and all, the overhead really isn't really always worth it. If you're developing an SDK or OSS package and you need changelogs, sure. Other than that, really, what's the point?
You can always water it down. The point is to have some order in the commits. Otherwise is just messy.
Any standard that wastes valuable space in the first line of the commit is a hard sell. I don't see the point in including fix/feat/feat! just for the sake of "easy" semantic versioning because generally you know if the next release is going to be major or minor and patches are generally only only after specific bugs. Scanning the commits like this also puts way too much trust in people writing good commit messages which nobody ever seems to do.
Also, I fucking hate standards that use generic names like this. It's like they're declaring themselves the correct choice. Like "git flow".
You can always adapt to your how repo. But yeah, that's the point. If you can trust people to make changes on a repo then you should be able to trust them in using some kind of commit structure.
Generic names are probably used in order to crate a familiar, easy to remember, structurized commit format.
The generic name I'm complaining about is "conventional commits", not "fix" and "feat"
NGL I 'm a bit like that. I often do "work" commits so that my working tree is a bit more clean/I can go from working state to working state easily.
But before a PR, I always squash it, and most times it's just a single commit
Same haha. But i use a combination of commits ( but not pushed ), ammending, fixups and usually clean it up before making a PR or pushing ( and rebase/merge main branch while at it). Its how git should be used..
I do push often as I'm often switching between two devices. And I do make draft PR so I got an easy git diff that I can live reference with
You are not alone. This is the work git was built for.
There is a bit of benefit if you have code reviewed so separate commits are easier to review instaed of one -900 +1278 commit.
How do you "squash" it?
Squashing
The
s"squash" command is where we see the true utility of rebase. Squash allows you to specify which commits you want to merge into the previous commits. This is what enables a "clean history." During rebase playback, Git will execute the specified rebase command for each commit. In the case of squash commits, Git will open your configured text editor and prompt to combine the specified commit messages. This entire process can be visualized as follows:
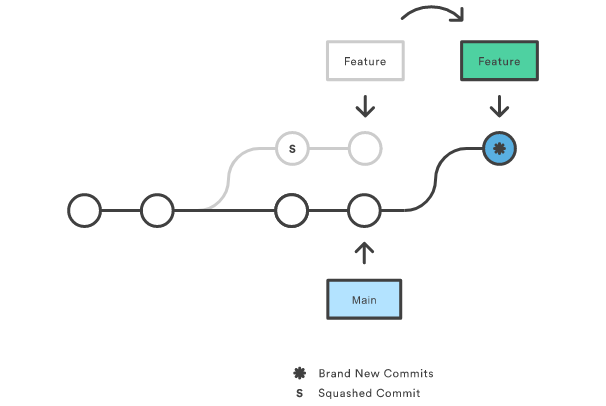
Note that the commits modified with a rebase command have a different ID than either of the original commits. Commits marked with pick will have a new ID if the previous commits have been rewritten.
https://www.atlassian.com/git/tutorials/rewriting-history
You can also amend for a softer approach, which works better if you don't push to remote after every commit.
The
git commit --amendcommand is a convenient way to modify the most recent commit. It lets you combine staged changes with the previous commit instead of creating an entirely new commit. It can also be used to simply edit the previous commit message without changing its snapshot. But, amending does not just alter the most recent commit, it replaces it entirely, meaning the amended commit will be a new entity with its own ref. To Git, it will look like a brand new commit, which is visualized with an asterisk (*) in the diagram below.
You can keep amending commits and creating more chunky and meaningful ones in an incremental way. Think of it as converting baby steps into an adult step.
My attempt to explain was squashed by this comment
Or if you want to --force commit 😈. Imo if it's my own working feature branch on a trunk-based roll-forward repo idgaf about rewriting history, and I will do it with wanton abandon.
Gitlab has a checkbox for squashing merge requests into a single commit. Not sure if GitHub has that too.
My ass who was sending patches to cyanogenmod gerrit ten years ago would never.
device: msm8916-common: BoardConfig: Build libril from source
Sometimes I'm in awe at the effort people put into these memes. Well done 😄
P.S Now make one about people who squash 100 commits into one without cleaning up the message and have a single commit with 1k added / 2k removed in it for the sake of "clean" history.
Yesssss, so true. Anytime people say they want history to be "clean" I insist they explain what they mean because more often than not they're going to suggest something that makes the history way less useful.
To real, it hurts
What tying your self worth to a commit graph looks like..