Nice try:)
This long, image-heavy article will pose a challenge to @AutoTLDR. Let’s see how it fares.
I hope it will be useful, thanks for testing it :)
AFAIK the way it works is that the more frequent a long sequence is, the more likely it is to get a single token. I'm not sure the fact that English is tokenized in the most efficient way is because they explicitly made it prefer English or if it is just a result of the corpus containing mostly English text.
What post? Where?
Here people actually react to what I post and write. And they react to the best possible interpretation of what I wrote, not the worst. And even if we disagree, we can still have a nice conversation.
Does anyone have a good theory about why the threadiverse is so much friendlier? Is it only because it's smaller? Is it because of the kind of people a new platform like this attracts? Because there is no karma? Maybe something else?
Did I miss something? Or is this still about Beehaw?
Here is an example of tokenization being biased toward English (using the author's Observable notebook):

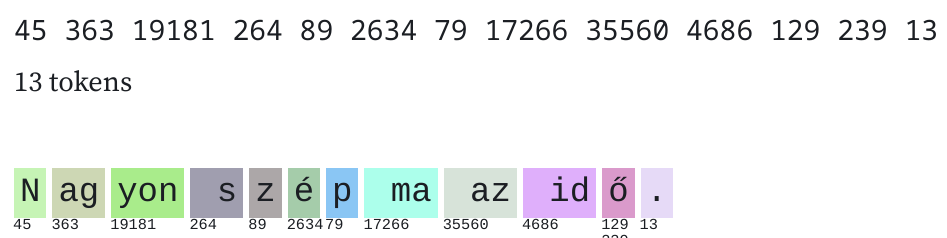
This is the same sentence in English and my native Hungarian. I understand that this is due to the difference in the amount of text available in the two languages in the training corpus. But it's still a bit annoying that using the API for Hungarian text is more expensive :)
The best hacker is of course the one who can guess the password the fastest (all-lowercase, dictionary word).
5
Embracing change and resetting expectations - Terence Tao about using GPT-4
(unlocked.microsoft.com)
7
Embracing change and resetting expectations - Terence Tao about using GPT-4
(unlocked.microsoft.com)
Original tweet: https://twitter.com/emollick/status/1671528847035056128
Screenshots (from the tweet):
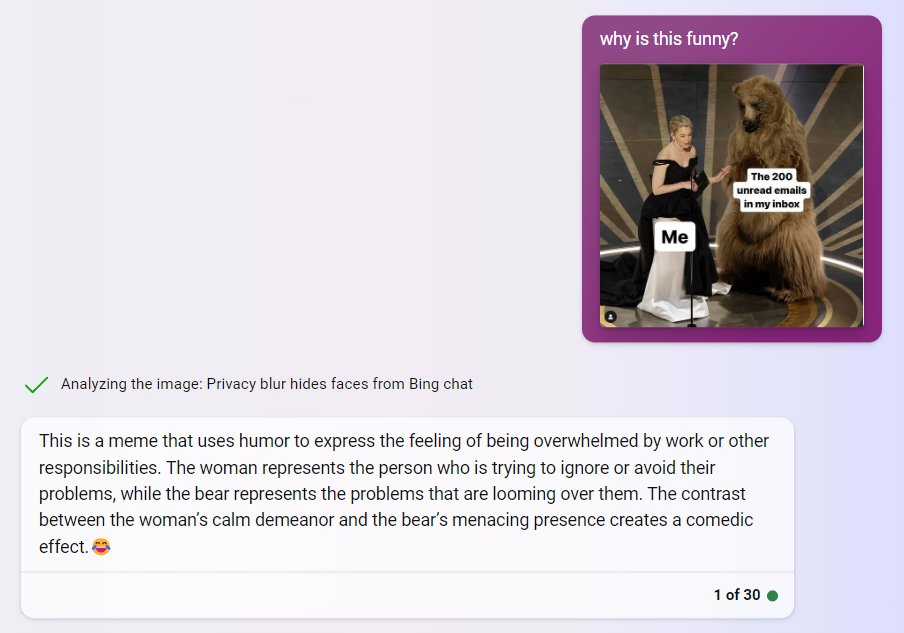
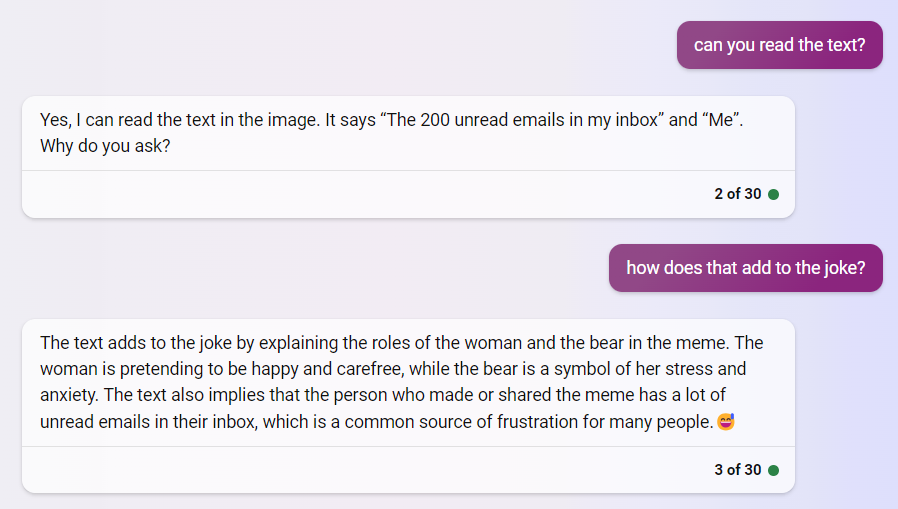

Old but gold.

Let’s try it this way:
https://rentry.co/evuft
(The bot probably couldn’t extract the text from that js-heavy site you linked to)