I'm just so exhausted these days. We have formal SLA's, but its not like they're ever followed. After all, Customer X needs to be notified within 5 minutes of any anomalous events in their cluster, and Customer Y is our biggest customer, so we give them the white glove treatment.
Yadda yadda, bla bla. So on and so forth, almost every customer has some exception/difference in SLAs.
I was hired on to be an SRE, but I'm just a professional dashboard starer at this point. The amount of times I've been alerted in the middle of the night because CPU was running high for 5 minutes is too damn high. Just so I can apologize to Mr. Customer that they maybe had a teensy slowdown during that time.
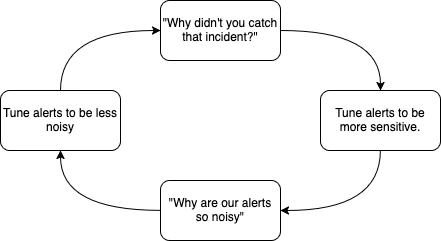
If I try to get us back to fundamentals and suggest we should only alert on impact, not short lived anomalies, there is some surface level agreement, but everyone seems to think "well we might miss something, so we need to keep it".
It's like we're trying to prevent outages by monitoring for potential issues rather than actually making our system more robust and automate-able.
How do I convince these people that this isn't sustainable? That trying to "catch" incidents before they happen is a fools errand. It's like that chart about the "war on drugs" where it shows exponential expense growth as you try to prevent ALL drug usage (which is impossible). Yet this tech company seems to think we should be trying to prevent all outages with excessive monitoring.
And that doesn't even get into the bonkers agreements we make with customers to agree to do a deep dive research on why 2 different environments have a response time that differs by 1ms.
Or the agreements that force us to complete customer provided training - while not assessing how much training we already committed to. It's entirely normal to do 3-4x HIPAA / PCI / Compliance trainings when everyone else in the org only has to do one set of those.
I'm at a point where I'm considering moving on. This job just isn't sustainable and there's no interest in the org to make it sustainable.
But perhaps one of y'all managed to fix something similar in their org with a few key conversations and some effort? What other things could I try as a sort of final "Hail Mary" before looking to greener pastures?
Nah, it's spam, OP has posted the same question at P.D multiple times across various communities. Dude either somehow doesn't know forum ettiquite or is a bot.