Edit, since folks don't seem to get the joke: Obama's campaign slogan was "Hope"

I'm glad the judge is really only considering the use of AI. Because it's obviously not copyright infringement to train AI with whatever TF materials you want. It's the output that matters.
Copyright infringement can't happen at all until the copyrighted material gets distributed somehow. If you make a thousand copies of a song at home you have not violated copyright law. If—however—you share that song with someone else (or the entire Internet) you just violated the copyright of whoever owned that song (assuming it's just a regular track and not something licensed in some special way).
Is it ethical to pirate a billion books to train AI? I don't know. They never really intended for humans to read them. So—to me—it's not that much different than the "making a thousand copies of a song at home" point. They haven't deprived the authors of anything at that point.
When the AI is used it may violate an author's copyright but only if it's close enough to the original work that a judge would say, "yeah, that's definitely derivative."
bows in solemn gesture
Are there any other websites that still let you put in your AIM and ICQ numbers? Or brag about your super low user ID? 19437 BTW 🤣
They will do this but then what option will they have left when they make it even more bloated and slow—since they now have this "extra room", as it were?
At my daughter's (high) school the kids have to manage social media accounts as part of the curriculum. They're an arts school that puts on plays, musical performances, etc.
It is fully expected that the kids post tasteful videos promoting their work (e.g. a pianist kid would have to post a video of them playing and they'll be taught how to make sure the lighting/audio is right). They also have the kids create all the school's social media videos (only certain teachers have the power to actually post them though).
They are taught what's bad and good about social media and they experience it. All the teachers know everyone's (non-secret, haha) accounts and they get graded on them! There's all sorts of resources for the kids and they're all so damned professional it's easy to forget they're just kids.
Things like bullying, how to manage comments/inappropriate posts, and how to deal with trolls/unhelpful negative feedback is covered and it's fucking fantastic.
Every school should have social media management and online etiquette classes.
What I wish they spent more time on is how to protect your privacy... But I understand the conflict there: If they teach the kids how to keep things secret, well, parents might not appreciate that 🤷
LEGO Representative: "What's the likelihood..."
This guy: "Never tell me the odds!"
Meh. Seems rather plane.
I'm pining for an answer to this question myself.
Totally unfair comparison. Reek was tortured and had his balls forcibly cut off to become what he was.
Rubio was like that from the start.
A president that doesn't believe in civil rights and due process deserves neither.
Edit, since folks don't seem to get the joke: Obama's campaign slogan was "Hope"
“...this is not a gun problem. This is a mental health problem, this is a social problem, this is a cultural problem, this is a spiritual problem." -Donald J Trump in April 2023

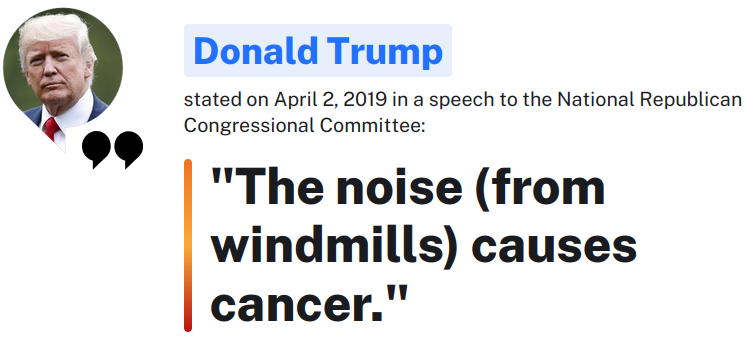
A simple reminder of the incompetence, idiocy, and insanity that was the Trump presidency. Here's the original story, in case you forgot:
https://www.politico.com/story/2019/09/05/hurricane-dorian-sharpie-trump-1482839



It's really hard to get SD to output something like a cat girl hugging a fox girl so I decided to learn how to use the "segment anything" extension for a1111. The first results were great!

Got the trifecta: A fox girl hugging a bunny girl who was also being hugged by a cat girl.
But now I wanted to take it further: Can I get five different anime beast people's hugging? No, LOL. Now yet anyway 🤣
That's supposed to be a a fox girl, a bunny girl, a cat girl, a frog girl, and a horse girl (like Pretty Derby).


Generated by Bing DALL-E 3


Try the chips.