How complicated is it to have a CNAME? /s
farcaller
joined 1 year ago
You can delegate to isolated nameservers with DNS-01, there's no need to have control over the primary zone: https://www.eff.org/deeplinks/2018/02/technical-deep-dive-securing-automation-acme-dns-challenge-validation
I don’t think your question relates to the language as much as to the platform. The language of choice is somewhat irrelevant and what you care about is what actually happens under the hood.
For the likes of java and go you want to have some understanding of what runtime does for the memory allocations and how their GCs work. For python you sometimes end up in the spots where you need to understand what limitations the GIL imposes (even more important now that they are trying to get rid of it). When you run C (or C++ or Rust) on the embedded hardware it really helps to understand what exactly bit flipping does in specific registers and what DMA means for how you write your code.
You don’t really have to know it all. You can absolutely write code without caring about anything of that and I know plenty software engineers that do. Some people write amazing functional things in java without ever questioning what it does to the machines and what resources you need to run it.
If you start questioning it, that will only expand your understanding. It's not a lateral move from e.g. C to Rust where you need to learn a lot to write your code in a memory-safe way, it's a movement deeper into the stack and what you learn there will be applicable to any language you use for this stack.
Answering your question: I always feel bad about not understanding some low-level concept. I have stacks of MCU reference docs lying around, printed, highlighted; I have archives with sample code, and hand-annotated CMSIS reversing notes. Embedded world is hard because you can’t just know C and be done with it. You have to know the hardware, too.
Here's my advice for you. Make notes of things that you learn from people smarter than you. Create a web of those notes and see where your gaps are. Then, work on learning something in those gaps in particular and see if you can make a blog post or something of your own. When you share what you learn you become one of those people with deep understanding that others look up to. There's always someone struggling with something that you either know or know how to figure it out.
ECC is slightly more required for ZFS because its ARC is generally more aggressive than the usual linux caching subsystem. That said, it's not a hard requirement. My curent NAS was converted from my old windows box (which apparently worked for years with bad ram). Zfs uncovered the problem in the first 2 days by reporting the (recoverable) data corruption in the pool. When I fixed the ram issue and hash-checked against the old backup all the data was good. So, effectively, ZFS uncovered memory corruption and remained resilient against it.
Garage is trivial to get up and running and it’s more lightweight than minio nowadays.
No. It's my in-cluster storage that I only use for things that are easier to work with via S3 api, and I do backups outside of the k8s scope (it's a bunch of various solutions that boil down to offsite zfs replication, basically). I'd suggest you to take a look at garage's replication features if you want it to be durable.
Actual public services run there, yeah. In case if any is compromised they can only access limited internal resources, and they'd have to fully compromise the cluster to get the secrets to access those in the first place.
I really like garage. I remember when minio was straightforward and easy to work with. Garage is that thing now. I use it because it's just co much easier to handle file serving where you have s3-compatible uploads even when you don’t do any real clustering.
Between homebrew and nix, the amount of foss macs can run out of the box is pretty close to some generic Ubuntu (nixpkgs is technically the largest repo out there, but not all of the nixpkgs are available on mac).
I’ve dealt with exactly the same dilemma in my homelab. I used to have 3 clusters, because you'd always want to have an "infra" cluster which others can talk to (for monitoring, logs, docker registry, etc. workloads). In the end, I decided it's not worth it.
I separated on the public/private boundary and moved everything publicly facing to a separate cluster. It can only talk to my primary cluster via specific endpoints (via tailscale ingress), and I no longer do a multi-cluster mesh (I used to have istio for that, then cilium). This way, the public cluster doesn’t have to be too large capacity-wise, e.g. all the S3 api needs are served by garage from the private cluster, but the public cluster will reverse-proxy into it for specific needs.
any oauth (I use kanidm) and oauth2-proxy solves that and now you can easily use passkeys to log into your intranet resources.
The biggest certainty is that just having an open port for an SMTP server dangling out there means you will 100% be attacked.
True.
Not just sometimes, non-stop.
True
So you don't want to host on a machine with anything else on it, cuz security.
I don’t think "cuz security" is a proper argument or no one would be ever listening on public internet. Are there risks? Yes.
So you need a dedicated host for that portion
Bullshit. You do not need a dedicated host for smtp ingress. It won’t be attacked that much.
and a very capable and restrictive intrusion detection system (let's say crowdsec), which is going to take some amount of resources to run, and stop your machine from toppling over.
That's not part of the mail pipeline the OP asked for.
Here, I brought receipts. There are two spikes of attempted connections in the last month, but it's all negligible traffic.
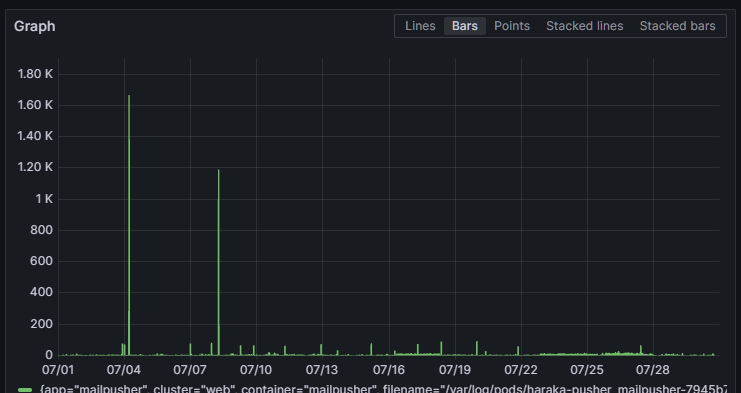
Self-hosting mail servers is tricky, same as self-hosting ssh, http, or whatever else. But it's totally doable even on an aging RPi. No, you don’t need to train expensive spam detection because it's enough to have very strict rules on where you get mail from and drop 99% of the traffic because it will be compliant. No, you don’t need to run crowdstrike for a server that accepts bytes and stores them for another server (IMAP) to offer them to you. You don’t even need an antivirus, it's not part of mail hosting, really.
Instead of bickering and posturing, you could have spent your time better educating OP on the best practices, e.g. like this.
view more: next ›
Updates to DNS, yes. Not necessarily to your primary zone. In other words, you don’t need access to the name servers for your highly privileged example.com zone, only the nameservers for inconsequential.example.com. With the challenge delegation you can easily narrow the scope by CNAMEing the relevant _acme-challenge enries in your primary domain once. This not only removes the need for the validator to modify your primary zone, but also scopes what subdomains it can validate, too. So the blast radius decreases.
I, too, maintain several devices that insist on having the certificates (and keys, yuck) being fed to them by hand. I automated it all, because I don’t see why a human should be in a loop of copying the secret material. Automaton is good.