I created this account two days ago, but one of my posts ended up in the (metaphorical) hands of an AI powered search engine that has scraping capabilities. What do you guys think about this? How do you feel about your posts/content getting scraped off of the web and potentially being used by AI models and/or AI powered tools? Curious to hear your experiences and thoughts on this.
#Prompt Update

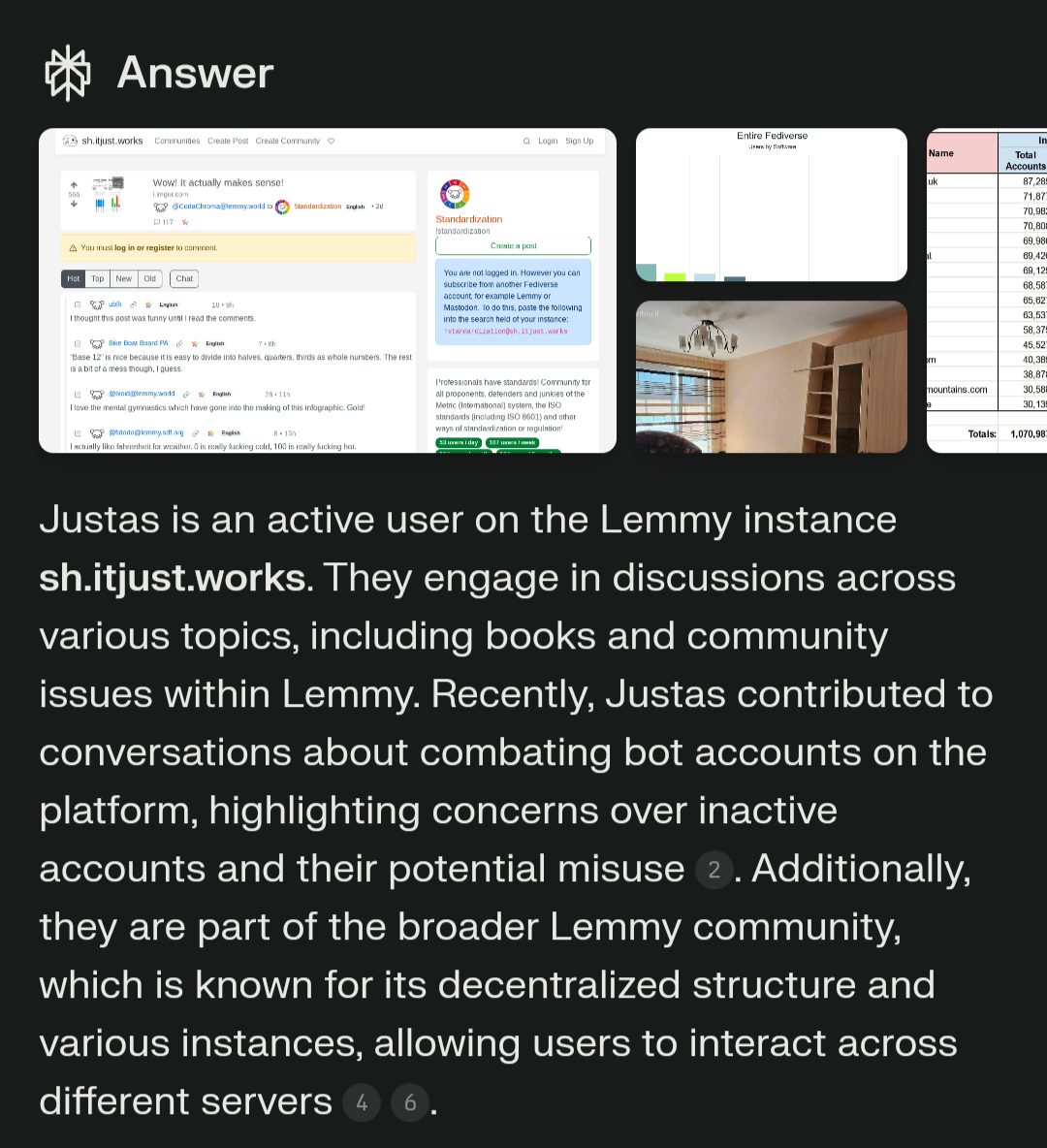
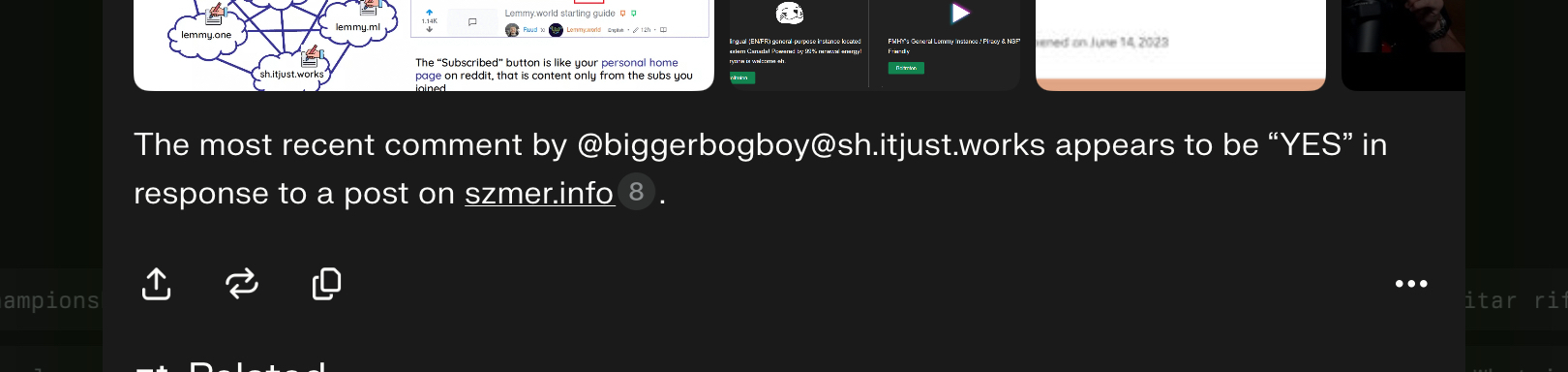
The prompt was something like, What do you know about the user [email protected] on Lemmy? What can you tell me about his interests?" Initially, it generated a lot of fabricated information, but it would still include one or two accurate details. When I ran the test again, the response was much more accurate compared to the first attempt. It seems that as my account became more established, it became easier for the crawlers to find relevant information.
It even talked about this very post on item 3 and on the second bullet point of the "Notable Posts" section.
For more information, check this comment.
Edit¹: This is Perplexity. Perplexity AI employs data scraping techniques to gather information from various online sources, which it then utilizes to feed its large language models (LLMs) for generating responses to user queries. The scraping process involves automated crawlers that index and extract content from websites, including articles, summaries, and other relevant data. It is an advanced conversational search engine that enhances the research experience by providing concise, sourced answers to user queries. It operates by leveraging AI language models, such as GPT-4, to analyze information from various sources on the web. (12/28/2024)
Edit²: One could argue that data scraping by services like Perplexity may raise privacy concerns because it collects and processes vast amounts of online information without explicit user consent, potentially including personal data, comments, or content that individuals may have posted without expecting it to be aggregated and/or analyzed by AI systems. One could also argue that this indiscriminate collection raise questions about data ownership, proper attribution, and the right to control how one's digital footprint is used in training AI models. (12/28/2024)
Edit³: I added the second image to the post and its description. (12/29/2024).