Guy is the real Forget-Me-Not
Pyro
joined 2 years ago
Oh my god I had no idea there was a device selection and the Android one feels so much better. Please keep it as the default for new Android users.
Most of that greentext is bullshit. The truth is that some people will always try to make a quick buck, even at the expense of others.
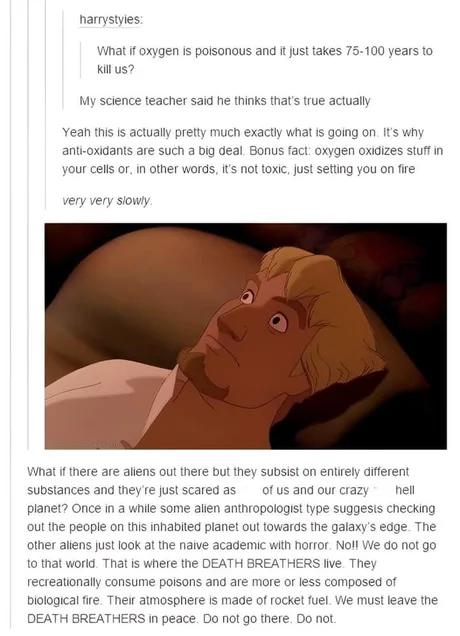
Here's the thing...
For the uninitiated:
Created Nov 2023
Oof that's quite a long-standing bug. Thanks for letting me know, I'll follow it on GitHub.
Climate change is the most likely reason.
Peak ZeroWaste
How dare you
Even though I have the Up button set to Show Parent in settings, it's not showing up for comments.
view more: next ›
June 5, let's gooo !!!