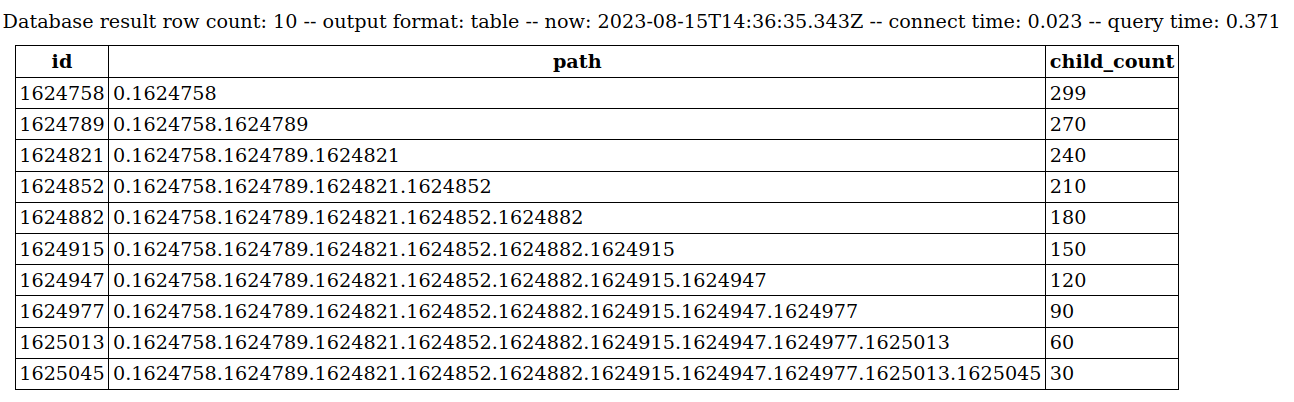
lemmy_server PostgreSQL table for comment does not keep parent comment id directly, it uses a path field of ltree type.
by default, every comment has a path of it's own primary key id.
comment id 101, path = "0.101"
comment id 102, path = "0.102"
comment id 103, path = "0.101.103"
comment id 104, path = "0.101.103.104"
comment 103 is a reply to comment 101, 104 is a reply to 103.
A second table named comment_aggregates has a count field with comment_id column linking to comment table id key. On each new comment reply, lemmy_server issues an update statement to update the counts on every parent in the tree. Rust code issues this to PostgreSQL:
if let Some(parent_id) = parent_id {
let top_parent = format!("0.{}", parent_id);
let update_child_count_stmt = format!(
"
update comment_aggregates ca set child_count = c.child_count
from (
select c.id, c.path, count(c2.id) as child_count from comment c
join comment c2 on c2.path <@ c.path and c2.path != c.path
and c.path <@ '{top_parent}'
group by c.id
) as c
where ca.comment_id = c.id"
);
sql_query(update_child_count_stmt).execute(conn).await?;
}
I've been playing with doing bulk INSERT of thousands of comments at once to test SELECT query performance.
So far, this is the only SQL statement I have found that does a mass UPDATE of child_count from path for the entire comment table:
UPDATE
comment_aggregates ca
SET
child_count = c2.child_count
FROM (
SELECT
c.id,
c.path,
count(c2.id) AS child_count
FROM
comment c
LEFT JOIN comment c2 ON c2.path <@ c.path
AND c2.path != c.path
GROUP BY
c.id) AS c2
WHERE
ca.comment_id = c2.id;
There are 1 to 2 millions comments stored on lemmy.ml and lemmy.world - ~~this rebuild of child_count can take hours, and may not complete at all. Even on 100,000 rows in a test system, it's a harsh UPDATE statement to execute.~~ EDIT: I found my API connection to production server was timing out and the run-time on the total rebuild isn't as bad as I thought. With my testing system I'm also finding it is taking under 19 seconds with 312684 comments. The query does seem to execute and run normal, not stuck.
Anyone have suggestions on how to improve this and help make Lemmy PostgreSQL servers more efficient?
EDIT: lemmy 0.18.3 and 0.18.4 are munging the less-than and greater-than signs in these code blocks.