
- I was applying to a job, and then I had to answer a question about web scraping, which I'm not familiar with. I answered all the other questions with no issue, so I decided might as well put in the effort to learn the basics and see if I can do it in a day.
- Yes, it was *somewhat * easier than I expected, but I still had to watch like 4 YouTube videos and read a bunch of reddit and stack overflow posts.
- I got the code working, but I decided to run it again to double-check. It stopped working. Not sure why.
- Testing is also annoying because the "web page" is a google doc and constantly reloads or something. It takes forever to get proper results from my print statements.
- I attached an image with the question. I haven't heard back from them, and I've seen other people post what I think might be this exact question online, so hopefully I'm not doing anything illegal.
- At this point, I just want to solve it. Here's the code:
from bs4 import BeautifulSoup
import requests
import pandas as pd
import numpy as np
def createDataframe(url): #Make the data easier to handle
#Get the page's html data using BeautifulSoup
page = requests.get(url)
soup = BeautifulSoup(page.text, 'html.parser')
#Extract the table's headers and column structure
table_headers = soup.find('tr', class_='c8')
table_headers_titles = table_headers.find_all('td')
headers = [header.text for header in table_headers_titles]
#Extract the table's row data
rows = soup.find_all('tr', class_='c4')
row_data_outer = [row.find_all('td') for row in rows]
row_data = [[cell.text.strip() for cell in row] for row in row_data_outer]
#Create a dataframe using the extracted data
df = pd.DataFrame(row_data, columns=headers)
return df
def printMessage(dataframe): #Print the message gotten from the organised data
#Drop rows that have missing coordinates
dataframe = dataframe.dropna(subset=['x-coordinate', 'y-coordinate'], inplace=True)
#Convert the coordinate columns to integers so they can be used
dataframe['x-coordinate'] = dataframe['x-coordinate'].astype(int)
dataframe['y-coordinate'] = dataframe['y-coordinate'].astype(int)
#Determine how large the grid to be printed is
max_x = int(dataframe['x-coordinate'].max())
max_y = int(dataframe['y-coordinate'].max())
#Create an empty grid
grid = np.full((max_y + 1, max_x + 1), " ")
#Fill the grid with the characters using coordinates as the indices
for _, row in dataframe.iterrows():
x = row['x-coordinate']
y = row['y-coordinate']
char = row['Character']
grid[y][x] = char
for row in grid:
print("".join(row))
test = 'https://docs.google.com/document/d/e/2PACX-1vQGUck9HIFCyezsrBSnmENk5ieJuYwpt7YHYEzeNJkIb9OSDdx-ov2nRNReKQyey-cwJOoEKUhLmN9z/pub'
printMessage(createDataframe(test))
My most recent error:
C:\Users\User\PycharmProjects\dataAnnotationCodingQuestion\.venv\Scripts\python.exe C:\Users\User\PycharmProjects\dataAnnotationCodingQuestion\.venv\app.py
Traceback (most recent call last):
File "C:\Users\User\PycharmProjects\dataAnnotationCodingQuestion\.venv\app.py", line 50, in <module>
printMessage(createDataframe(test))
File "C:\Users\User\PycharmProjects\dataAnnotationCodingQuestion\.venv\app.py", line 30, in printMessage
dataframe['x-coordinate'] = dataframe['x-coordinate'].astype(int)
~~~~~~~~~^^^^^^^^^^^^^^^^
TypeError: 'NoneType' object is not subscriptable
Process finished with exit code 1
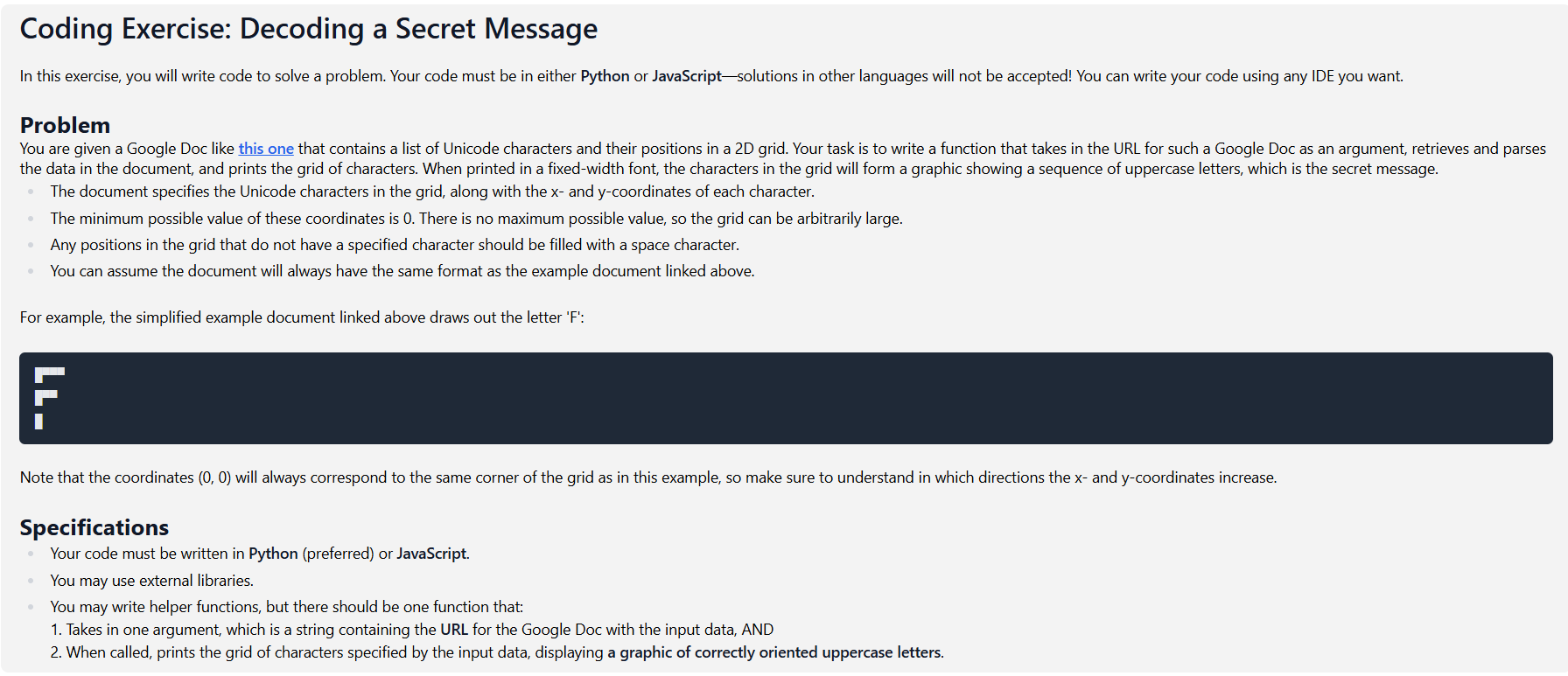
I turned it in days ago so there's nothing I can do about it. But I'll keep that in mind for the future.