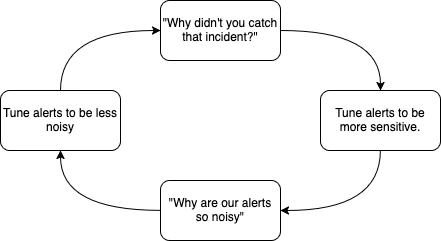
Maybe, one of these days, my SRE team can define SLOs that actually make sense. This "alert on whatever the customer wants" stance really really sucks.
Whether you're just learning about Site Reliability Engineering/Software Reliability Engineering or you're a seasoned on-call warrior, you're in the right place.
SRE (Site Reliability Engineering - AKA Software Reliability Engineering) is a discipline that uses software engineering principles to ensure that systems are reliable, scalable, and resilient. It’s about balancing feature velocity with system stability—keeping things running even when they shouldn’t.
Here are a few ideas to get started:
This community is part of the programming.dev network. Please make sure to:
Maybe, one of these days, my SRE team can define SLOs that actually make sense. This "alert on whatever the customer wants" stance really really sucks.
If you're lucky, you work somewhere where nobody ever checks if any problems came from not having caught an incident. In that case, the top-right half of the diagram just disappears and developers get the privilege of... you know... sleep.
Some of the stories I have from the last place I worked, though.
When they first announced that devs would be on-call (including at 3:00am) for when the automated systems decided there was an issue, I panicked and pushed for creating a program that could do first-tier on-call support (based on rules that the devs owned, of course.)
And there were so many dumb situations where some downstream system borked and I ended up on a call all night literally unable to do anything. I figured this system could 1) weed out false positives, 2) identify when the problem was legitimate but not something my team could do anything about, 3) let us tell it to suppress certain types of alerts just for the night (if it was an issue worth looking into, but not one that needed dealt with before business hours), and 4) even take remediative action in some cases.
Folks told me all that was great. By the time it was done and ready to actually use, they'd changed their minds and decided none of what I'd specifically asked them to ok at the outset complied with their secret, unwritten "policy".
I ended up quitting that place over their absolutely cruel on-call policies. (And other things, but the on-call was the worst bit.)
Definitely not that lucky. We have customers who seem to watch dashboards and create a Sev1 anytime latency degrades by 10%. They explain to their account manager that they need to have perfect performance all the time. The AM then comes to us demanding that we increase the sensitivity of the alert. Management agrees. And then, voila, just like that we have an alert that flaps all day and all night that we aren't "allowed" to remove until someone can show that the noise is literally stopping us from catching other stuff.
It's insanity.
EDIT: I only stay because new leadership seems like they want to fix it earnestly. And things are headed in the right direction, but it takes a long time to turn a ship.