this post was submitted on 01 Apr 2024
1217 points (99.2% liked)
Linux
48214 readers
731 users here now
From Wikipedia, the free encyclopedia
Linux is a family of open source Unix-like operating systems based on the Linux kernel, an operating system kernel first released on September 17, 1991 by Linus Torvalds. Linux is typically packaged in a Linux distribution (or distro for short).
Distributions include the Linux kernel and supporting system software and libraries, many of which are provided by the GNU Project. Many Linux distributions use the word "Linux" in their name, but the Free Software Foundation uses the name GNU/Linux to emphasize the importance of GNU software, causing some controversy.
Rules
- Posts must be relevant to operating systems running the Linux kernel. GNU/Linux or otherwise.
- No misinformation
- No NSFW content
- No hate speech, bigotry, etc
Related Communities
Community icon by Alpár-Etele Méder, licensed under CC BY 3.0
founded 5 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
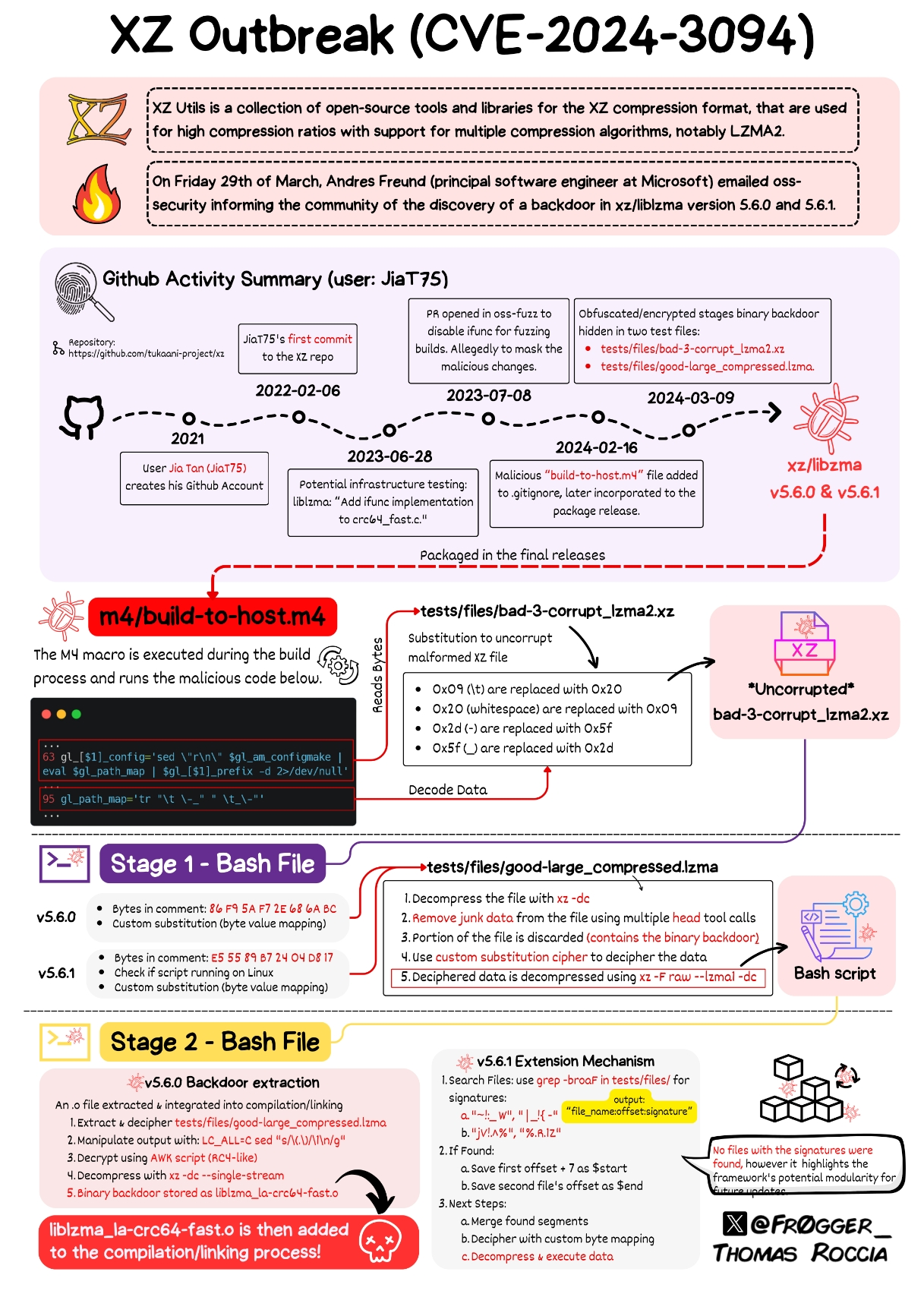
I know this is being treated as a social engineering attack, but having unreadable binary blobs as part of your build/dev pipeline is fucking insane.
It's not uncommon to keep example bad data around for regression to run against, and I imagine that's not the only example in a compression library, but I'd definitely consider that a level of testing above unittests, and would not include it in the main repo. Tests that verify behavior at run time, either when interacting with the user, integrating with other software or services, or after being packaged, belong elsewhere. In summary, this is lazy.
The test blobs belong in whatever repository they're used.
It's comically dumb to think that a repository won't include tests. So binary blobs like this absolutely do belong in the repository.
A repo dedicated to non-unit-test tests would be the best way to go. No need to pollute your main code repo with orders of magnitude more code and junk than the actual application.
That said, from what I understand of the exploit, it could have been avoided by having packaging and testing run in different environments (I could be wrong here, I've only given the explanation a cursory look). The tests modified the code that got released. Tests rightly shouldn't be constrained by other demands (like specific versions of libraries that may be shared between the test and build steps, for example), and the deploy/build step shouldn't have to work around whatever side effects the tests might create. Containers are easy to spin up.
Keeping them separate helps. Sure, you could do folders on the same repo, but test repos are usually huge compared to code repos (in my experience) and it's nicer to work with a repo that keeps its focus tight.
It's comically dumb to assume all tests are equal and should absolutely live in the same repo as the code they test, when writing tests that function multiple codebases is trivial, necessary, and ubiquitous.
It's also easier to work if one simple git command can get everything you need. There is a good case for a bigger nono-repo. It should be easy to debug tests on all levels else it's hard to fix issues that the bigger tests find. Many new changes in git make the downsides of a bigger repo less hurtful and the gains now start to outweigh the losses of a bigger repo.
A single git command can get everything for split repos if you use submodules
I would say yes and no, but yes the clone command can do it. But branching and CI get a bit more complicated. Pushing and reviewing changes gets more complicated to get the overview. If the functionality and especially the release cycle is different the submodules still have great values. As always your product and repo structure is a mix of different considerations and always a compromise. I think the additions in git the last years have made the previous really bad pain points with bigger repos less annoying. So that I now see more situations it works well.
I always recommend keeping all testing in the same repo as the code that affects the tests. It keeps tracking changes in functionality easier, needing to coordinate commits, merging, and branches in more than one repo is a bigger cognitive load.